Look at the screenshots below, one at a time for about a second or two, and write down the numbers of the items, one number for each screenshot, that you would most likely click first if those were real search results.
Ready? Go.
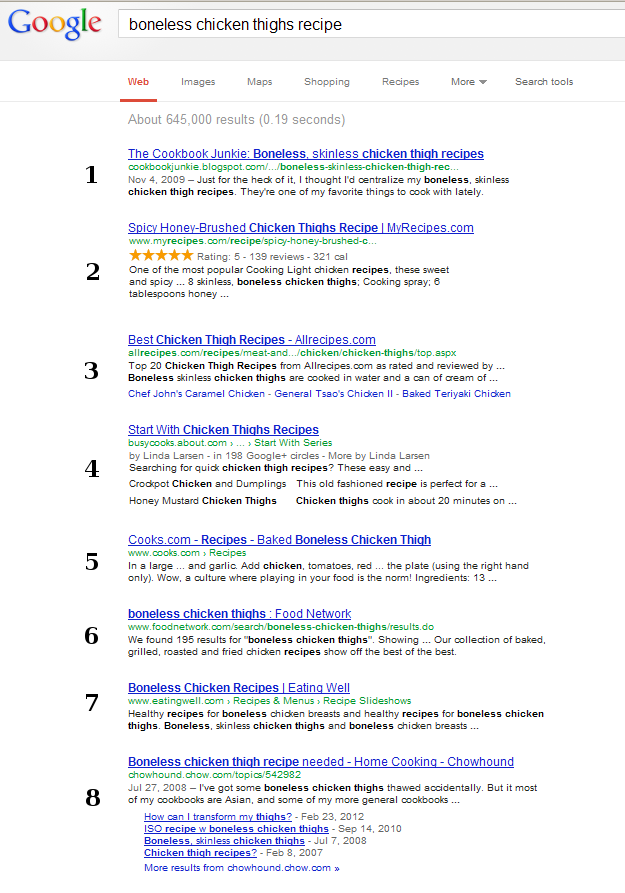
One more:

Finally, the last one:

It is more than likely that in the first case you picked #2, in the second - #6, and in the third - #2. Now, examine the screenshots more carefully and try to understand why you picked what you picked.
I am sure that you have figured it out.
The first two cases are, obviously, trivial. In the third, you were presented with eight choices, of which five have the same number of stars, and four of those five contain images of about the same quality. Those four (maybe, five), probably were the ones you considered. Since #2 has the highest number of votes, it became your ultimate pick. You may or may not have read the titles, and I am positive that you did not read the little snippets of text. So, you made your decision by just comparing four (or five) numbers and picking the highest. You were able to do that quickly because the results under consideration were structured in a consistent manner, which allowed you to scan them instead of reading.
Like it or not, that's exactly how most web users behave.
Lesson to be learned:
Although it is important for your web site to come up at the top in search engines, it is not enough anymore. It is also necessary to help search engines "understand" the structure of the information, so that they can present it to human users in a structured and more easily digestible form.
-
Google calls these structured snippets of information "rich snippets". They have been around since 2008 when Yahoo! SearchMonkey came into being. In 2009, Google started doing pretty much the same. In 2010, Yahoo! SearchMonkey service was discontinued while Google kept working on its rich snippets. The basic idea of both products was/is to extract structured data from web pages in order to (in Google's own words):
- "help search engines better understand your content" and
- "give users a sense for what’s on the page and why it’s relevant to their query".
As you may have noticed, the operative phrase here is "structured data". Why? Because, even though computers today are impressively fast, they are still disappointingly dumb when it comes to "understanding" information packaged for human consumption. But, if you "tell" them where the data is and how it is structured, they can be extremely efficient. For example, they can extract thousands, or even millions, of... recipes how to prepare chicken thighs... :-)
I am almost 100% sure that you are not reading this because you want to publish your recipes on the web. I am using recipes as examples only because they have simple data structure and make it a lot easier to explain the basics of how this technology works. So, even though you must be sick and tired of recipes by now, let's look at some more.
What may seem like a regular search result page in screenshot 4 below actually isn't.

Here is what we have:
- 1 - The usual keyword search box.
- 2 - Search is performed only in what the search engine believes to be recipes.
- 3, 4 and 5 - Search results can be narrowed down (filtered) by the amount of calories, preparation time and ingredients (#5, the drop-down for ingredients, is shown in screenshot 5 below).

-
3a, 4a and 5a - The recipes found actually have "fields" that correspond to filters 3, 4, and 5.
-
Instead of running just a simple keyword search of everything on the web, we asked the search engine to show us only the results that, in addition to containing the keywords we supplied, also meet all of the following requirements: each result must be a recipe, the caloric value of the dish must be under 500 cal, the time necessary for preparation must be under 30 min, and the recipe must not require Five-spice powder.
As you know now, Google, while indexing web pages, didn't really "figure out" any of those things on its own. Instead, it "was told" what pages or parts of pages are recipes, what parts of the recipes are ingredients, prep time, etc. Here is a mildly technical explanation of how Google "recognizes" all those things. If that is still too technical, below is my conceptual explanation of how it works.
A content publisher "tells" the search engine that a page or a part of a page is a recipe by enclosing it into special tags (to make it easier to digest, I use pseudo-markup):
<recipe> Recipe goes here.
</recipe>
<recipe> </recipe> tags:
<recipe>
<image> Image, if any, goes here.
</image>
<instructions> Some explanations go here.
<ingredients> Ingredients go here.
</ingredients>
<prep_time> Prep time goes here.
</prep_time>
</instructions>
<calories> Calories go here.
</calories>
<reviews>
<rating> Average rating, if any, goes here.
</rating>
<number_of_reviews> Number of reviews, if any, goes here.
</number_of_reviews>
</reviews>
</recipe>
-
Note: Let me repeat, just in case, that the above is not how the real mark-up is supposed to look. I made up all those tags in order to show the structure. In real life, one wold use something like RDFa, microformats or microdata, but we are not going to go there now.
Human users see a regular web page (tags are not rendered by the web browser), but a search engine sees structured data and knows exactly what part of the page represents what (provided, of course, the mark-up is not messed up). The search engine then displays those bits and pieces of structured data in a predictable, consistent and, therefore, human-user-friendly way. Because a recipe, in addition to the free-form-text directions, has at least three other "fields" (caloric value, cooking time, and ingredients; I am under the impression that those are "required" to qualify for inclusion into recipe search, but I may be wrong), users can filter search results by those properties. Image and review "fields" may or may not be present. If they are present, they are shown. If they aren't, they aren't shown. Technically, results could be filtered by those as well (e.g., show only recipes with average rating of at least 4.5 reviewed by at least 10 people), but Google does not provide such feature.
I hope, on a conceptual level, this is more or less clear now. Again, I am intentionally oversimplifying things for the sake of clarity.
No comments:
Post a Comment