
On the other hand... a Taoist tale many of us are familiar with thanks to J. D. Salinger comes to mind (in case you don't remember, see below):
-
Duke Mu of Chin said to Po Lo: "You are now advanced in years. Is there any member of your family whom I could employ to look for horses in your stead?" Po Lo replied: "A good horse can be picked out by its general build and appearance. But the superlative horse - one that raises no dust and leaves no tracks - is something evanescent and fleeting, elusive as thin air. The talents of my sons lie on a lower plane altogether; they can tell a good horse when they see one, but they cannot tell a superlative horse. I have a friend, however, one Chiu-fang Kao, a hawker of fuel and vegetables, who in things appertaining to horses is nowise my inferior. Pray see him." Duke Mu did so, and subsequently dispatched him on the quest for a steed. Three months later, he returned with the news that he had found one. "It is now in Shach'iu" he added. "What kind of a horse is it?" asked the Duke. "Oh, it is a dun-colored mare," was the reply. However, someone being sent to fetch it, the animal turned out to be a coal-black stallion! Much displeased, the Duke sent for Po Lo. "That friend of yours," he said, "whom I commissioned to look for a horse, has made a fine mess of it. Why, he cannot even distinguish a beast's color or sex! What on earth can he know about horses?" Po Lo heaved a sigh of satisfaction. "Has he really got as far as that?" he cried. "Ah, then he is worth ten thousand of me put together. There is no comparison between us. What Kao keeps in view is the spiritual mechanism. In making sure of the essential, he forgets the homely details; intent on the inward qualities, he loses sight of the external. He sees what he wants to see, and not what he does not want to see. He looks at the things he ought to look at, and neglects those that need not be looked at. So clever a judge of horses is Kao, that he has it in him to judge something better than horses." When the horse arrived, it turned out indeed to be a superlative animal.
-
-- J. D. Salinger, Raise High the Roof Beam, Carpenters
Joking aside, what I am trying to say - yet again - is that computers, although impressively fast, are still disappointingly dumb, and that they perform very poorly when it comes to processing human language, which is inherently ambiguous. To make things even harder for computers, humans often make it even more ambiguous.
In fact, in June 2011, having introduced Schema.org (initiated by Google), the world's four leading search engines pretty much admitted that they do not have production-ready technology capable of "understanding" what a web page really means and tried to off-load part of the job onto webmasters (humans) by encouraging them to add semantic markup to their web pages. I have written about it before, so I am not going to go into detail here again.
So much for the introduction.
General-purpose search engines, like Google, deal with enormous number (about 60 trillion) of texts of almost infinite variety, both structure- and meaning-wise. At the same time, they have nearly unlimited resources allowing them to go way beyond plain keyword indexing. Still, complex queries generally return poor results.
Now, let's scale the problem down. Let's say we have to deal with a reasonably small (in "computer terms") number of text files all of which have fairly uniform structure. The structure looks kind of like this (obviously, it is a resume):
<resume>
<candidate>
<first_name> John </first_name><last_name> Doe </last_name><street_address> 1234 Some St. </street_address><city> Anyville </city><state> XY </state><zip_code> 12345 </zip_code><phone> 123-456-7890 </phone><email> jdoe@example.com </email></candidate>
<work_experience>
<job_1>
<start_date> 2010-01-01 </start_date><end_date> 2014-01-01 </end_date><job_title> Software Engineer, Sr. </job_title><employer> XYZ, Inc. </employer><duties>
Unstructured text describing candidate's job duties goes here. </duties>
</job_1>
<job_2>
<start_date> 2006-01-01 </start_date><end_date> 2009-12-31 </end_date><job_title> Software Engineer </job_title><employer> ZYX, Inc. </employer>
<duties> Unstructured text, often a lot of unstructured text, goes here. It describes candidate's job duties or whatever other relevant or irrelevant information he/she chooses to include. </duties>
</job_2>
-
...
</work_experience>
<education>
<education_1>
<start_date> 1996-01-01 </start_date><end_date> 2000-12-31 </end_date><major> Computer Science </major><degree> B.S. </degree><instituion> University of Hof </institution></education_1>
<education_2>
<start_date> 1992-01-01 </start_date><end_date> 1996-12-31 </end_date><major> n/a </major><degree> n/a </degree><instituion> PS #123 </institution></education_2>
-
...
</education>
</resume>
The above uniform structure allows an Applicant Tracking System (commonly referred to as "ATS") to parse a resume and "stuff" its "pieces" into database tables (as I have stated before, I have yet to see at least one ATS that parses resumes well, but that's an entirely different story). The table structure may look kind of like this (I am somewhat oversimplifying things, of course):
Table 1:
candidate
| candidate_id | first_name | last_name | street_address | city | state | zip_code | phone | |
|---|---|---|---|---|---|---|---|---|
| 1234 | John | Doe | 1234 Any St. | Anyville | XY | 12345 | 123-456-7890 | jdoe@example.com |
Table 2:
work_experience
| job_id | candidate_id | start_date | end_date | job_title | employer | duties | keywords |
|---|---|---|---|---|---|---|---|
| 12345 | 1234 | 2010-01-01 | 2014-01-01 | Software Engineer, Sr. | XYZ, Inc. | Unstructured text describing candidate's job duties goes here. | MySQL, database, manage, content, project |
| 12346 | 1234 | 2006-01-01 | 2009-12-31 | Software Engineer | ZYX, Inc. | Unstructured text, often a lot of unstructured text, goes here. It describes candidate's job duties or whatever other relevant or irrelevant information he/she chooses to include. | SQL Server, database, test |
keywords (shown in blue). It contains keywords that may have been extracted from the unstructured text in the duties column if it were a real resume. For this example, I made up the keywords (let's just pretend that the duties column contains those keywords).
Table 3:
education
| edu_id | candidate_id | start_date | end_date | major | degree | institution |
|---|---|---|---|---|---|---|
| 12455 | 1234 | 1996-01-01 | 2000-12-31 | Computer Science | B.S. | University of Hof |
| 12456 | 1234 | 1992-01-01 | 1996-12-31 | n/a | n/a | PS #123 |
With resumes in the database, I, the "imaginary recruiter", can perform all kinds of searches. For example I can find all candidates:
- whose first name is John (why anyone would want to run such a pointless query is another question, but I can);
- within a certain area code or a few area codes;
- who have completed at least four years of college;
- with at least a certain number of years worth of total work experience;
- etc.
- If I am an ageist, I can filter out applicants who finished high school, say, before 1983.
- I can combine multiple criteria and perform complex searches.
- I can even automate such complex searches and use them... well, to do about anything (e.g., send recruiter spam).
Problems arise when, instead of using unambiguous values as search criteria (I deliberately limited the examples above to only such), one starts dealing with the most important part of a resume: what the candidate did in each of the jobs (to predict what he or she can do for your company/client).
For a computer, whatever gems may be hidden in those fragments of unstructured text in the
duties column are nothing but long strings of characters. Yes, you can search for words and phrases, but bear in mind that, for a computer, there is absolutely no difference between the character strings "manage" as in "project manager", "manage" as in "content management", "manage" as in "database management system", "manage" as in "managed staff", "manage" as in "manager's special", etc. Some ATS perform what is known as "keyword stemming" in order to reduce different word forms and parts of speech to some "common denominator" keywords (e.g., managed, manages, management, managing, manager, and manager's can be stemmed to a single keyword "manage"). It's a nice feature, but it may actually lead to even more ambiguity.

100 weighted keywords (crudely stemmed) extracted from a real resume.
To be objective, I have to say that some of the better ATS do try to overcome the above limitation by using some basic natural language processing techniques. For example, they may try to differentiate between "managing staff" and "managing data" by evaluating proximity of those words in the text. Some ATS use controlled vocabularies to label, index and categorize texts (in theory, a nice concept that rarely works as expected in real life). There are other techniques aimed at reducing natural language's inherent ambiguity. Again, they all "kind-of-sort-of" work, but they are extremely far from reliable.
Whatever techniques a particular ATS vendor may use, all of them market themselves as using "state-of-the-art", "cutting-edge" natural language processing and artificial intelligence technologies, "sophisticated" algorithms, etc. I am sure you've heard those. Unfortunately, most of it is pure hype. Technically, they are not lying because, of course, there are algorithms, and there probably are some of the above-mentioned or similar rudimentary natural language processing and artificial intelligence techniques built in. As to the "state-of-the-art", "cutting-edge", and "sophisticated", those are just fluffy epithets that cannot be quantified.
Let's be realistic. If Google
- can't "figure out" who I am (last time I checked I wasn't a woman; about 5'9" and under 140 lb, I can hardly be described as "plus-size"; not interested in boxing or any kind of punching - bags or fellow humans; not particularly flirty; couldn't care less about knitwear... well, you get the drift)
- and "assumed" that Truman Capote sent an article to The New York Times from his grave,
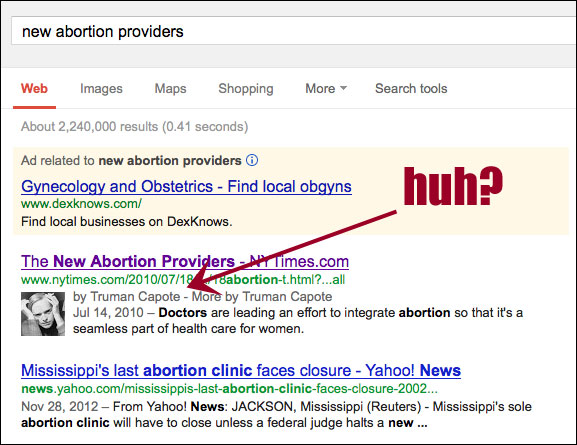

So, should you just ditch your ATS and go back to fumbling with paper resumes? - Of course, not. But you need to understand its strengths and weaknesses in order to use the full potential of the former and somehow work around the latter.
Let's list some of the strengths first:
- Applicant Tracking Systems save trees.
- They allow to perform complex searches. As long as you use unambiguous search criteria (dates, numbers, strings with unique meaning), your searches should return reliable results. To some extent, it depends on how well the resume parser works and whether it puts all the "resume pieces" into the right columns of the database, but most ATS allow applicants to correct parser errors (whether all applicants do that or not is another question).
- The tracking component of an ATS is a handy tool to categorize candidates, schedule and track appointments/interviews with them, annotate their records, generate reports, send notifications, and what not. There isn't much to talk about here: tracking is tracking, whether you track customers, students, patients, donations, or job seekers. All such software applications are fundamentally the same. By the way, as the name "Applicant Tracking System" implies, this initially was the primary functionality of this type of software.
Let's look at the weaknesses now. Well, the fundamental weakness is what this whole post is about: any (existing) Applicant Tracking System is not smart enough to replace humans. This means that you may rely on your ATS to do short-listing, but you must be aware that your automatically generated short list will:
- always be "polluted" with some applicants who are not qualified, under-qualified, and over-qualified (this may be corrected "manually", provided, of course, that your short list actually is short enough for a human to clean up);
- never include all qualified candidates (this one is very difficult to correct "by hand").
If you, as a recruiter, are comfortable with this state of things, keep using your ATS and be happy. If not, check back for the next installment (when and if I find the time to write it).
P.S. For the uninitiated who don't know how Applicant Tracking Systems work, Faizan Patankar of Career Geek wrote an intentionally oversimplified explanation with a chart.
P.P.S. On a philosophical note, think about this:
-
"Artificial intelligence need not be the holy grail of computing. The goal instead could be to find ways to optimize the collaboration between human and machine capabilities – to let the machines do what they do best and have them let us do what we do best."
- Walter Isaacson, The Intersection of the Humanities and the Sciences, National Endowment for the Humanities 2014 Jefferson Lecture (scroll down for the lecture text).
No comments:
Post a Comment